Anchor Base 和 Anchor Free
本文最后更新于 2023年9月18日 上午
Anchor Base 和 Anchor Free
1 概念
1.1 什么是 Anchor
Anchor也叫做锚,其实是一组预设的边界框用于在训练时学习真实的边框位置相对于预设边框的偏移。通俗点说就是预先设置目标可能存在的大概位置,然后再在这些预设边框的基础上进行精细化的调整。而它的本质就是为了解决标签分配的问题。
锚作为一系列先验框信息,其生成涉及以下几个部分:
- 用网络提取特征图的点来定位边框的位置;
- 用锚的尺寸来设定边框的大小;
- 用锚的长宽比来设定边框的形状;
通过设置不同尺度,不同大小的先验框,就有更高的概率出现对于目标物体有良好匹配度的先验框约束。
![[2-科研/笔记/data_md/Pasted image 20221230171124.png]]
目标检测算法一般可分为anchor-based、anchor-free、两者融合类。
三者的区别就在于有没有利用anchor提取候选目标框。
1.2 如何使用 Anchor
在传统的图像处理时期,要想检测出图像中的目标,通常先提取图像特征,然后编码成一串串特征描述子送入机器学习的分类器中进行判别。比如HOG特征提取器通过滑窗+金字塔的方式逐个抠图,这种基于区域的方式在深度学习中得到了延续。
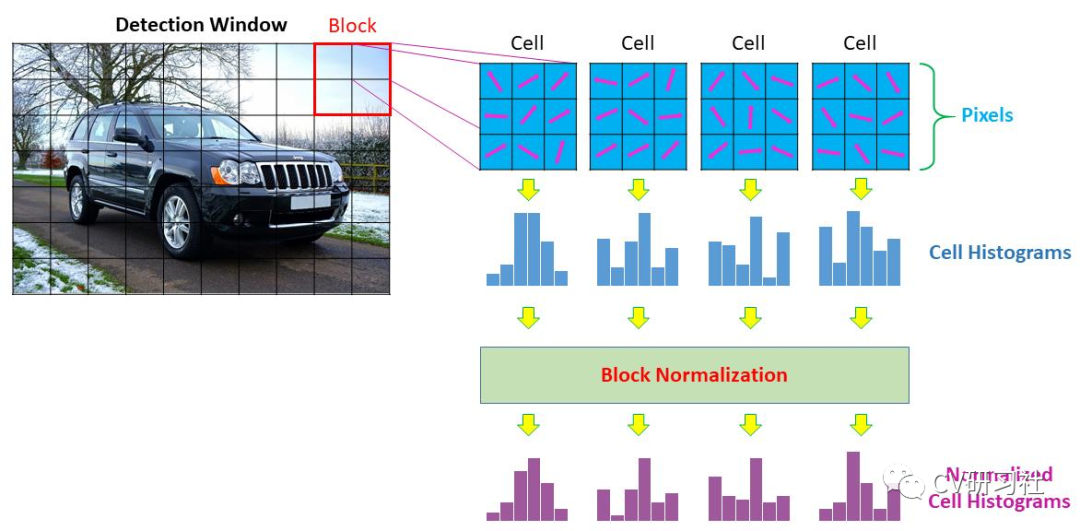
anchor(也被称为anchor box)是在训练之前,在训练集上利用k-means等方法聚类出来的一组矩形框,代表数据集中目标主要分布的长宽尺度。
在两阶段的目标检测分支中,暴力滑窗获得区域的思想逐步演化出锚的概念,从Faster RCNN网络开始正式基于anchor回归坐标,通过RPN的策略生成候选框。
在单阶段的目标检测分支中,从SSD到YOLOv2,v3,v4,v5都延续着基于anchor做回归的路线。
这里小伙伴们会发现怎么把YOLOv1漏了?
YOLOv1只有区域划分的思想而没有锚框的概念,虽然将图片网格化后在每个网格中预测目标,但是尺度的回归是在整个图像中,所以该网络出来时检测精度相比同期作品低了一大截,这也是为什么YOLO的后期版本均加入了锚框的思想,在锚框的约束下使模型的精准度和召回率都有了质的提升。
2 Anchor Free 与 Anchor Base
2.1 Anchor Free
代表算法:CornerNet、ExtremeNet、CenterNet、FCOS等;
Anchor-Free即无先验锚框,直接通过预测具体的点得到锚框。
基于Anchor-Free的目标检测算法有两种方式:
- 关键点检测方法,通过定位目标物体的几个关键点来限定它的搜索空间;
- 通过目标物体的中心点来定位,然后预测中心到边界的距离。
最直接的好处就是不用在训练之前对当前训练数据聚类出多个宽高的anchor参数了。
2.1.1 基于关键点的检测算法
此类方法将目标检测问题转换成关键点定位组合来解决,下面介绍几种关键点检测算法:
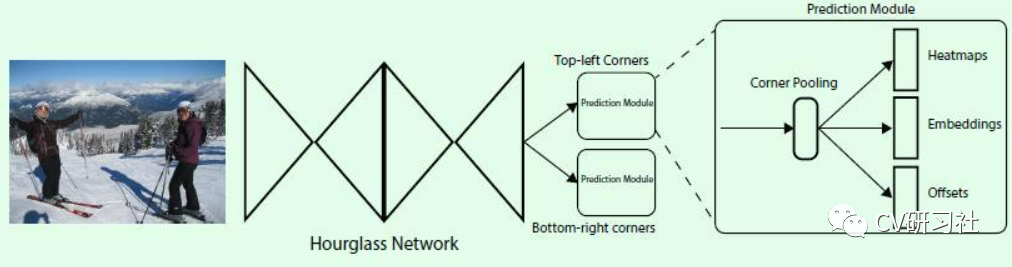
CornerNet直接预测每个点是左上、右下角点的概率,通过左上右下角点配对提取目标框。
整个网络如下图所示:输入图像通过串联多个Hourglass模块做特征提取,然后输出两个分支,即左上角点预测分支和右下角点预测分支;每个分支模型经过Corner Pooling后输出三个部分:
- Heatmaps:预测角点位置
- Embeddings:预测的角点分组
- Offsets:微调预测框
Grid R-CNN算法基于RPN找到候选区域,对每个ROI特征独立的提取特征图。将特征图传到全卷积网络层里面输出概率的热度图,用于定位与目标物对齐的边界框的网格点;借助网格点通过特征图级别的融合,最终确定目标物的准确边界框。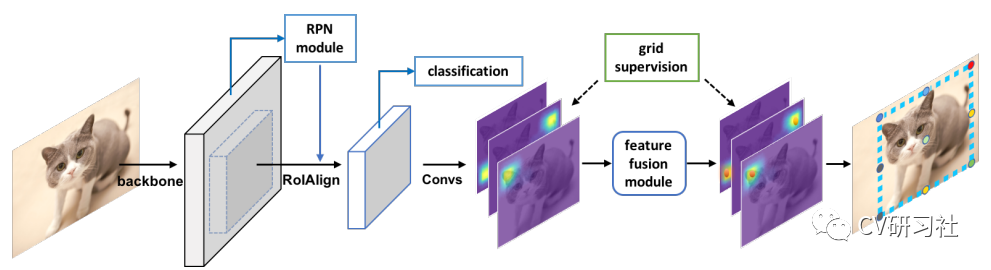
ExtremeNet算法通过串联多个Hourglass模块对每个目标预测5个关键点(上、下、左、右四个极点和一个中心点),如果五个关键点是几何对齐的,也就是说将不同热度图的极点进行组合,判断组合的几何中心是否符合中心点热图上的值的要求,再将它们分组到一个外接框中。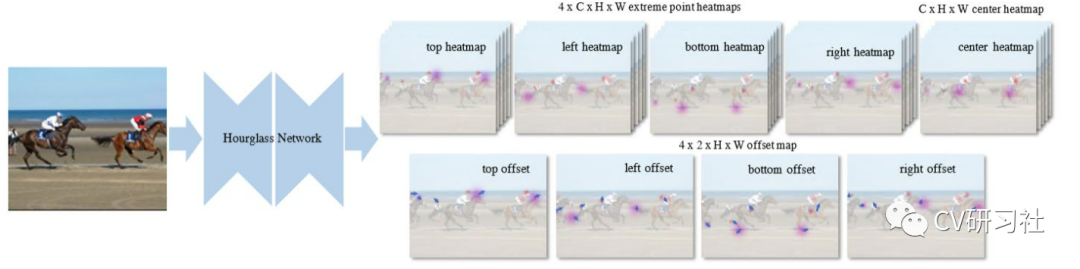
2.1.2 基于目标中心的检测算法
此类方法在构建模型时将其看作一个点,即目标框的中心点。检测器在回归中心点的同时得到它的相关属性。下面我们介绍几种基于目标中心的检测算法:
YOLO作为早期的一种anchor-free的算法,将目标检测作为一个空间分离的边界框和相关的类概率回归问题,可以直接从整张图片预测出边界框和分类分数。
但是它最后采用全连接层直接对边界框进行预测,由于图片中存在不同尺度和长宽比(scales and ratios)的物体,使得YOLO在训练过程中学习适应不同物体的形状比较困难。
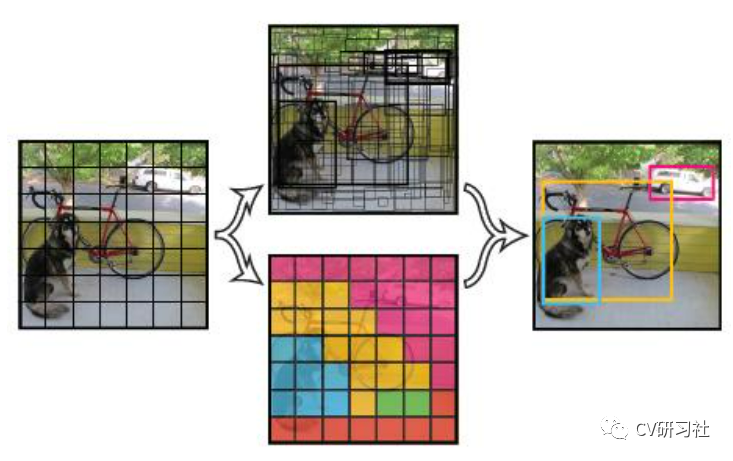
上面我们也提到YOLO由于在网络中没有预先假设框的大小和宽高比,所以在训练的过程中它除了知道每个网络输出几个检测框外,其他预设框的任何信息都一无所知。
CenterNet只需要提取目标的中心点,无需对关键点分组和后处理。这篇文章的网络结构较为清晰,从开源的代码中可以看到,采用编解码的方式提取特征(Resnet/DLA/Hourglass),输出端分为三块:
- Heatmap:预测中心点的位置;
- wh:对应中心点的宽高;
- reg:对应中心点的偏移;
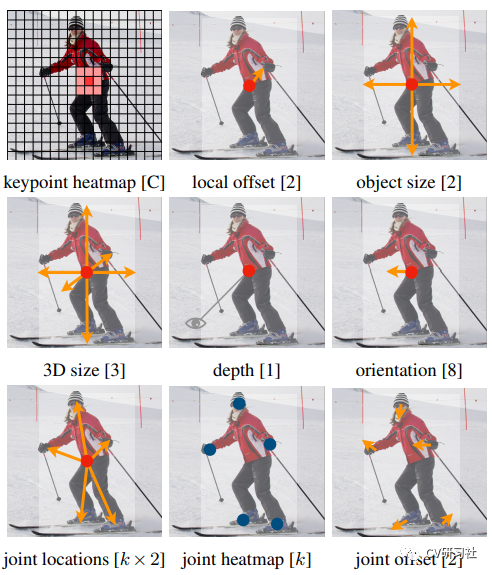
那么目标检测领域为什么又考虑去掉anchor呢?
- 预先设定的anchor尺寸需要根据数据集的不同做改变,可以人工设置或对数据集聚类得到;
- anchor的数量相比目标的个数多很多,造成正负样本的不均衡现象;
当然为了解决去掉anchor后目标尺度变化,类别不平衡等的问题,FPN,PAN,Focal loss等技术起到了很好的作用,通过FPN,PAN对不同层级特征的融合使得预测时使用的特征图中就包含了不同尺度的目标特征,这样就不需要用不同尺度的anchor来锁定目标尺寸再进行回归。而Focal loss对正负样本求损失时的加权也在一定程度上缓解了不平衡问题。
Anchor Free类算法归纳:
- 基于多关键点联合表达的方法:
- CornerNet/CornerNet-lite:左上角点+右下角点
- ExtremeNet:上下左右4个极值点+中心点
- CenterNet:Keypoint Triplets for Object Detection:左上角点+右下角点+中心点
- RepPoints:9个学习到的自适应跳动的采样点
- FoveaBox:中心点+左上角点+右下角点
- PLN:4个角点+中心点
- 基于单中心点预测的方法:
- CenterNet:Objects as Points:中心点+宽度+高度
- CSP:中心点+高度(作者预设了目标宽高比固定,根据高度计算出宽度)
- FCOS:中心点+到框的2个距离
2.2 Anchor Base
代表算法:Faster R-CNN、SSD、Yolo(2、3、4、5)等;
Anchor-Base即有先验锚框,先通过一定量的数据做聚类等方法得到一些锚框尺度与大小,然后结合先验锚框与预测偏移量得到预测锚框。
前几年目标检测领域一直被基于锚的检测器所统治,此类算法的流程可以分为三步:
- 在图像或者点云空间预设大量的anchor(2D/3D);
- 回归目标相对于anchor的四个偏移量;
- 用对应的anchor和回归的偏移量修正精确的目标位置;
2.2.1 基于单阶段的检测算法
在图像上滑动可能的锚点,然后直接对框进行分类。这两年单阶段的检测方法不断的扩充YOLO家族,常见的就有YOLOv1—v5,Complex-YOLO,YOLO3D,YOLO-Lite,Poly-YOLO,YOLOP等等,GitHub上一搜能有小几十个变形。
整体框架一般分为BackBone,Neck,Head三大块,基础特征部分其实ResNet-50就挺好了,或者采用CSP/C3等模块级联提取特征。Neck部分各个网络也都差不多,采用FPN或者PAN来融合高低层特征图信息。Head部分主要针对任务而定,如果做二维框检测就回归中心点,宽高,类别等信息;如果做三维框检测可以增加朝向角或者掩码图等等。
2.2.2 基于两阶段的检测算法
对每个潜在的框重新计算图像特征,然后将这些特征进行分类。这两年两阶段的新方法出现的比较少,在2D,3D或者前融合领域出现的两阶段检测算法还是依托于Faster-RCNN的理念。
两阶段检测算法主要还是RCNN系列,包括RCNN,Fast-RCNN,Faster-RCNN,Mask-RCNN等。其中RCNN和Fast-RCNN之间过渡了一个SPPNet。之后在Faster-RCNN框架的基础上出现了特征金字塔。然后Mask-RCNN融合了Faster-RCNN架构、ResNet和FPN,以及FCN里的分割方法来提升mAP。
下图是在网上找到的一张两阶段检测网络发展历程,从细分市场的角度描述的挺详细的,供小伙伴们对应学习:
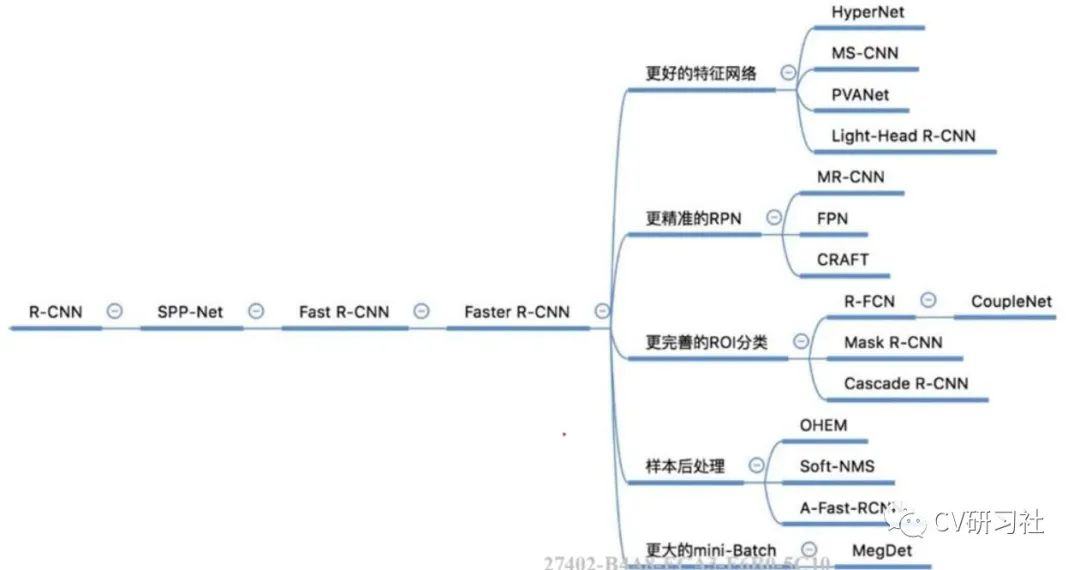
Faster R-CNN-设置了3种尺度3种宽高ratio一共9个anchor提取候选框
![[2-科研/笔记/data_md/Pasted image 20221230173904.png]]
2.3 融合方法
融合方法(融合anchor-based和anchor-free分支的方法)
代表算法:FSAF、SFace、GA-RPN等;
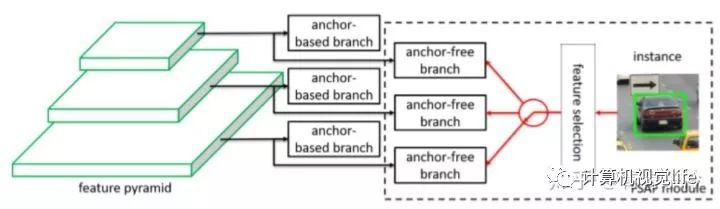
FSAF-既有根据先验设定的anchor-based分支,也有anchor-free分支增强对异常ratio目标的检测能力
3 扩展
3.1 Anchor Free 和 Anchor Base 区别几何
这个问题首先需要回答为什么要有 anchor。在深度学习时代,物体检测问题通常都被建模成对一些候选区域进行分类和回归的问题。在单阶段检测器中,这些候选区域就是通过滑窗方式产生的 anchor;在两阶段检测器中,候选区域是 RPN 生成的 proposal,但是 RPN 本身仍然是对滑窗方式产生的 anchor 进行分类和回归。
1. Feature Selective Anchor-Free Module for Single-Shot Object Detection
2. FCOS: Fully Convolutional One-Stage Object Detection
3. FoveaBox: Beyond Anchor-based Object Detector
4. High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection
而在上面几篇论文的 anchor-free 方法中,是通过另外一种手段来解决检测问题的。同样分为两个子问题,即确定物体中心和对四条边框的预测。预测物体中心时,具体实现既可以像 1、3 那样定义一个 hard 的中心区域,将中心预测融入到类别预测的 target 里面,也可以像 2、4 那样预测一个 soft 的 centerness score。对于四条边框的预测,则比较一致,都是预测该像素点到 ground truth 框的四条边距离,不过会使用一些 trick 来限制 regress 的范围。
3.2 为什么 anchor-free 能卷土重来
anchor-free 的方法能够在精度上媲美 anchor-based 的方法,最大的功劳我觉得应该归于 FPN,其次归于 Focal Loss。(内心OS:RetinaNet 赛高)。在每个位置只预测一个框的情况下,FPN 的结构对尺度起到了很好的弥补,FocalLoss 则是对中心区域的预测有很大帮助。当然把方法调 work 并不是这么容易的事情,相信有些细节会有很大影响,例如对重叠区域的处理,对回归范围的限制,如何将 target assign 给不同的 FPN level,head 是否 share 参数等等。
3.3 Anchor Free 和 Single Anchor
上面提到的 anchor-free 和每个位置有一个正方形 anchor 在形式上可以是等价的,也就是利用 FCN 的结构对 feature map 的每个位置预测一个框(包括位置和类别)。但 anchor-free 仍然是有意义的,我们也可以称之为 anchor-prior-free。另外这两者虽然形式上等价,但是实际操作中还是有区别的。在 anchor-based 的方法中,虽然每个位置可能只有一个 anchor,但预测的对象是基于这个 anchor 来匹配的,而在 anchor-free 的方法中,通常是基于这个点来匹配的。
3.4 Anchor Free 的局限性
虽然上面几种方法的精度都能够与 RetinaNet 相媲美,但也没有明显优势(或许速度上有),离两阶段和级联方法相差仍然较远。和 anchor-based 的单阶段检测器一样,instance-level 的 feature representation 是不如两阶段检测器的,在 head 上面的花样也会比较少一些。顺便吐槽一下,上面的少数 paper 为了达到更好看的结果,在实验上隐藏了一些细节或者有一些不公平的比较。
3.5 Anchor Free 的其他套路
anchor-free 除了上面说的分别确定中心点和边框之外,还有另一种 bottom-up 的套路,以 CornerNet 为代表。如果说上面的 anchor-free 的方法还残存着区域分类回归的思想的话,这种套路已经跳出了这个思路,转而解决关键点定位组合的问题。
4 展望
anchor-free 的方法由于网络结构简单,对于工业应用来说可能更加友好。对于方法本身的发展,我感觉一个是新的 instance segmentation pipeline,因为 anchor-free 天生和 segmentation 更加接近。一个是向两阶段或者级联检测器靠拢,进一步提高性能,如果能在不使用 RoI Pooling 的情况下解决 feature align 问题的话,还是比较有看头的。另外还有一个是新的后处理方法,同时也期待看到 anchor-free 的灵活性带来新的方法和思路。